Meta-Analysis Fundamentals and Core Methodologies: A Complete Technical Guide
Understanding the fundamentals of meta-analysis is not optional for researchers who want their quantitative syntheses to hold up under scrutiny — and the stakes are higher than most practitioners realize. For example, in fields like psychotherapy research and studies of the therapeutic alliance, the vast majority of published syntheses still fail to report a prediction interval. This means they are missing a critical statistical tool that directly answers the question every clinician actually cares about: what effect size should I expect with the next patient? This guide covers the essential methods of meta-analysis, from effect size computation through heterogeneity modeling, emphasizing the methodological rigor and transparency that modern psychological and clinical research requires.
Key Takeaways
| Question | Core Answer |
|---|---|
| What is meta-analysis? | A quantitative research synthesis technique that pools effect sizes across independent studies to produce a single, weighted estimate of an association or intervention impact. |
| What is the primary unit of analysis? | The effect size (Cohen’s d, Hedges’ g, Pearson’s r, Odds Ratio) — not the p-value. The complete meta-analysis course covers each metric in detail. |
| Which R packages are used for meta-analysis? | metafor and MAd are widely adopted packages; restricted maximum likelihood (REML) estimation is typically the default for random-effects models. |
| How do I convert a t-statistic or F-statistic to an effect size? | The compute.es live calculator and its companion R package convert t, F, means/SDs, p-values, ANCOVA outputs, binary data, and correlations into d, g, r, and OR automatically. |
| When should Hedges’ g replace Cohen’s d? | When sample sizes are small (N < 20), Cohen’s d carries an upward bias; Hedges’ g applies a correction factor to provide a more conservative, unbiased population estimate. |
| What is heterogeneity in meta-analysis? | Variability in effect sizes across studies beyond sampling error; quantified via I², Q-statistic, and tau² — but best interpreted through prediction intervals rather than I² alone. |
| What is PRISMA 2020? | The current reporting standard for systematic reviews and meta-analyses, featuring an expanded checklist with specific item/sub-item recommendations that substantially exceeds prior versions. |
A concise visual guide to the five essential steps in conducting a meta-analysis, highlighting core methodologies.
What Is Meta-Analysis? The Fundamentals and Core Methodologies Explained
When conducting a quantitative research synthesis or meta-analysis, relying solely on p-values is insufficient. The foundation of any quantitative synthesis relies on a different metric: the effect size.
A meta-analysis aggregates standardized effect estimates from multiple independent studies, weights them by their precision (typically using inverse variance weighting), and produces a pooled estimate along with its 95% Confidence Intervals (CI). The logic is straightforward — larger, more precise studies carry more weight; smaller studies contribute less, though they are not simply discarded.
The key distinction from a narrative review is decisive. Unlike a narrative review that tends to focus on dichotomous statistical significance (p < .05), an effect size provides a standardized measure of improvement or difference that can be aggregated across multiple independent studies. This is the definitional argument for why meta-analysis exists as a methodology, and it is a core concept every researcher must internalize before any computation begins.
Effect Size: The Core Metric of Meta-Analysis Fundamentals
An effect size is a quantitative index of the strength of the association between an independent variable (IV) and a dependent variable (DV). It is scale-free, which makes aggregation across heterogeneous studies possible.
The four most commonly encountered effect size metrics in psychological research are:
- Cohen’s d — Standardized mean difference between two groups
- Hedges’ g — Bias-corrected version of Cohen’s d, preferred in small-sample contexts
- Pearson’s r — Correlation coefficient, used when the primary association is correlational rather than experimental
- Odds Ratio (OR) — Effect size for binary outcome data (e.g., treatment response vs. non-response)
Each metric has a mathematical method for converting it to the others, which means a single synthesis can pool d from RCTs, r from observational studies, and OR from clinical trials — provided the conversions are executed correctly and documented transparently.
Cohen’s d and Hedges’ g: Meta-Analysis Core Methodology for Standardized Mean Differences
Based on Jacob Cohen’s widely adopted guidelines (1988) for the behavioral sciences, the magnitude of d is conventionally interpreted as:
- Small: d = .20
- Medium: d = .50
- Large: d = .80
These thresholds are descriptive conventions, not rigid inferential cutoffs. A d = .20 in a high-stakes clinical context may be practically significant even if it appears “small” by Cohen’s initial benchmarks.
While Cohen’s d is the standard, it has a known upward bias when sample sizes are extremely small (e.g., N < 20). Hedges’ g applies a correction factor to Cohen’s d to yield a more conservative, unbiased estimate of the population effect size. In practice, when a synthesis includes studies with very small sample sizes, defaulting to Hedges’ g is a methodologically defensible choice, and it is often the default output that R packages like metafor will prioritize in their model objects.
The formula for the correction factor in Hedges’ g involves multiplying Cohen’s d by J, where J is approximately 1 - (3/(4df - 1)) (with df = n₁ + n₂ - 2). For large samples, J converges to 1.0, making g and d functionally equivalent. For N = 10 per group, the correction is non-trivial and should always be applied.
In a comparative study of 200 systematic reviews using AMSTAR-2, only 29.8% of reviews received a positive rating on item 3 — whether authors adequately explained their selection of study designs for inclusion. This highlights that one of the most foundational validity decisions in any meta-analysis is frequently overlooked.
Converting Other Statistical Metrics: Core Methodologies for Real-World Data Extraction
Not all published papers provide pristine means and standard deviations. Often, researchers must extract an effect size from a published t-statistic, an F-statistic, or binary count data.
This is where data extraction requires careful attention to specific formulas and their implications for precision:
- Effect Size from T-Test (TES):
d = t × √(1/n₁ + 1/n₂)— direct and exact when group sample sizes are available. - Effect Size from F-Test (FES):
d = √(F × (1/n₁ + 1/n₂))— applicable only to one-degree-of-freedom F-statistics (i.e., two-group comparisons). - Effect Size from P-Value (PES): Requires back-converting to a t or z statistic first, then applying the standard formula. This introduces approximation error that should be clearly noted in the synthesis.
- Effect Size from ANCOVA: Requires the F-statistic, group sample sizes, and covariate R² to compute an adjusted d; ignoring the covariate adjustment systematically underestimates the treatment effect in RCTs that control for baseline covariates.
- Effect Size from Binary Data: Produces the log Odds Ratio and its standard error, then converts to d using the formula:
d = ln(OR) × √3/π. - Effect Size from Correlation (r): Converts directly to d via
d = 2r / √(1 - r²)— widely used when aggregating correlational and experimental literatures in a single synthesis.
The compute.es framework simplifies this process, allowing researchers to convert summary statistics (means, standard deviations, t-tests, F-tests) into robust effect size metrics like Cohen’s d, Hedges’ g, Pearson’s r, and Odds Ratios. Every conversion path listed above is implemented directly in the compute.es live app (as well as the compute.es R package on CRAN), with full documentation on the underlying formulas for each method.
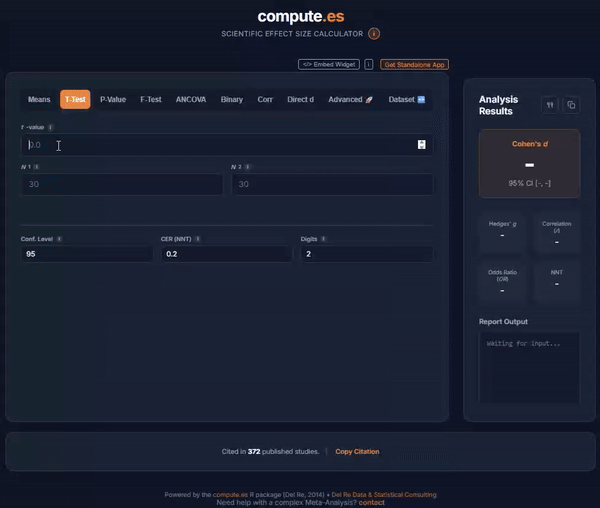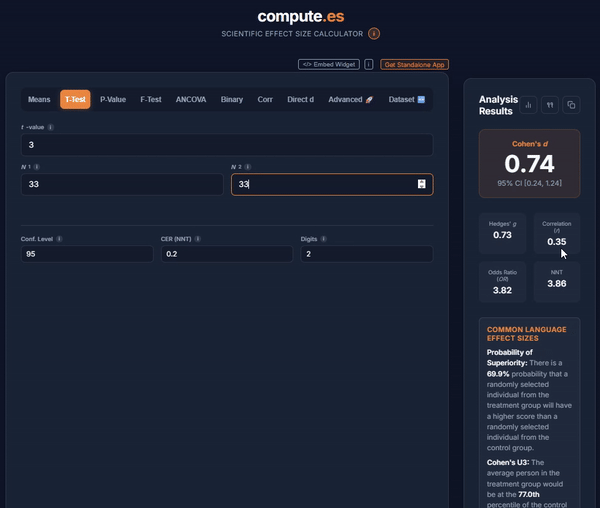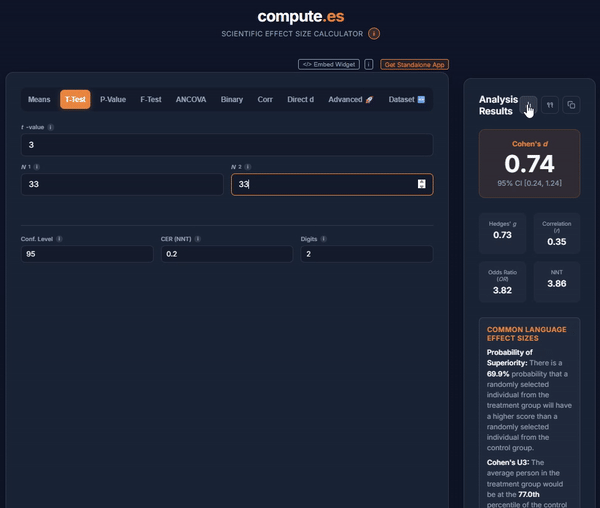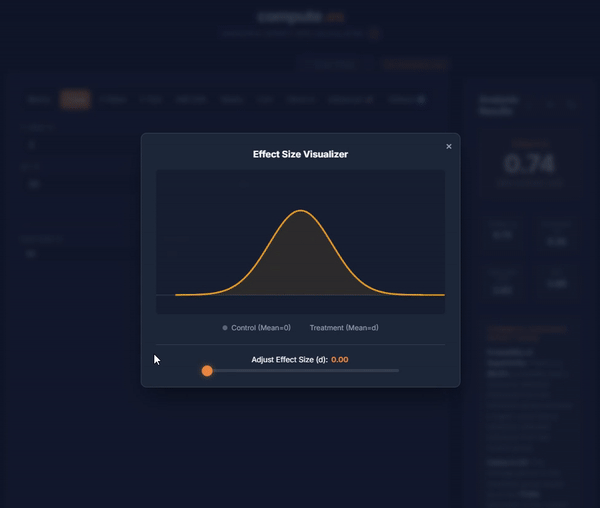
Standard Errors and Confidence Intervals: Precision in Meta-Analysis
The standard error (SE) of an effect size is the fundamental unit of precision in meta-analysis. It determines how much weight a given study contributes to the pooled estimate under inverse-variance weighting, and it feeds directly into the 95% CI calculation for each individual study shown in a forest plot.
For Cohen’s d, the approximate SE is: SE(d) = √((n₁ + n₂)/(n₁ × n₂) + d²/(2(n₁ + n₂))). For Pearson’s r (transformed to Fisher’s z), the SE simplifies cleanly to SE(z_r) = 1 / √(n - 3), which is why the z-transformation is a standard step before pooling correlation coefficients.
The compute.es toolkit automatically provides the standard error and 95% Confidence Intervals (CI) for every metric, ensuring your data is immediately ready for analysis in R packages like metafor or MAd. This removes the manual transcription step that historically introduced copy-paste errors into effect size databases, reducing mistakes and supporting transparent research practices.
The Compute.es FAQ provides additional guidance on when to use specific variance formulas (e.g., pooled vs. control-group standard deviation for Cohen’s d) and how the confidence interval width changes under different sample configurations.
Heterogeneity Assessment: Understanding Variance in Meta-Analysis
After computing and pooling effect sizes, the critical next question is: how much do individual study effects vary beyond what sampling error alone would predict? This addresses the heterogeneity problem, which relies on three primary metrics.
- Q-statistic: A chi-square test for homogeneity; a significant Q indicates more variance than expected by chance alone. However, it is underpowered when there are few studies and overpowered when there are many studies.
- I²: The proportion of total variance attributable to between-study variance (τ²) rather than sampling error; commonly interpreted as <25% low, 25–75% moderate, >75% high — but critically, I² is not an absolute measure of heterogeneity.
- Prediction Interval (PI): A 95% range within which the true effect in a new, comparable study is estimated to fall. This is arguably the most clinically relevant heterogeneity summary, yet it is the one most frequently omitted from published meta-analyses.
The distinction between I² and the prediction interval is not purely academic. An I² of 80% with a pooled d = 0.60 may sound alarming — but if the prediction interval runs from d = 0.20 to d = 1.00 (consistently positive), it suggests a very different clinical story than a prediction interval running from d = -0.40 to d = 1.60 (which crosses zero and implies potential harm). Prediction intervals provide a better interpretation of heterogeneity precisely because I² is relative.
Model selection for handling heterogeneity generally involves two principal frameworks: the fixed-effects model (which assumes a single true effect size underlying all studies, treating observed variation as pure sampling error) and the random-effects model (which assumes a distribution of true effects, estimating τ² via restricted maximum likelihood or similar methods). For psychological and clinical research, the random-effects model is almost universally the correct specification, given the inherent conceptual diversity of participants, interventions, and outcome measures across studies.
Multilevel and Hierarchical Frameworks in Meta-Analysis
Standard random-effects models assume independence across effect sizes — one study contributes one effect size. This assumption breaks down in several common scenarios that researchers encounter frequently in applied synthesis work.
Dependent effect sizes arise when a single study reports multiple outcomes from the same sample (outcome-level nesting), when multiple treatment arms are compared against a shared control group (arm-level nesting), or when studies are nested within specific research groups or laboratories. Ignoring this dependence deflates standard errors and artificially overstates precision.
The three-level multilevel meta-analytic model addresses this directly: Level 1 captures within-study sampling variance (σ²), Level 2 captures within-study between-effect-size variance (τ²_within), and Level 3 captures between-study variance (τ²_between). Implementing this in metafor via rma.mv() with an appropriate variance-covariance structure is the current methodological standard for any synthesis dealing with dependent data.
The fundamentals of meta-analysis include effect size synthesis, handling dependent data with multilevel approaches, and using transparent tools to support research synthesis. The multilevel model is often where practitioners first encounter the gap between textbook methods and real-world data structures. The Del Re portfolio provides applied examples of these frameworks across clinical and behavioral science literatures.
Publication Bias: Modern Adjustments and Selection Models
A meta-analysis that does not address publication bias is methodologically incomplete. The “file-drawer problem” — the systematic non-publication of null or negative findings — biases the available pool of effect sizes in a positive direction.
Modern approaches to publication bias have moved away from legacy imputation methods and toward sophisticated probabilistic modeling. The primary detection and adjustment tools for a current synthesis include:
- Funnel Plot Asymmetry & Egger’s Test: A scatter plot of effect sizes versus standard errors serves as the initial diagnostic. Egger’s regression provides a formal test of this asymmetry (where a significant intercept indicates bias), though researchers must note that it is severely underpowered when there are fewer than 10 studies.
- Selection Models (e.g., Vevea & Hedges): The current frequentist standard for adjustment. Rather than imputing missing studies, selection models specify a weight function that models the probability of a study being published based on its p-value (e.g., assigning different publication probabilities to p < .05 versus p > .05). This estimates a bias-corrected pooled effect size without relying entirely on the assumption of funnel plot symmetry.
- Robust Bayesian Meta-Analysis (RoBMA): A state-of-the-art framework for addressing publication bias. RoBMA uses Bayesian model averaging to combine the results of multiple models — some assuming publication bias (selection models, PET-PEESE) and some assuming no publication bias (standard fixed and random effects). It weights the final adjusted effect size based on the posterior probability of each model, providing a robust, data-driven adjustment.
- p-Curve and z-Curve Analysis: These methods examine the distribution of statistically significant p-values (or z-scores). A right-skew (more p-values just below .05) indicates true underlying effects; a flat or left-skew suggests questionable research practices or severe p-hacking.
Methodological Warning on Legacy Tools:
Historically, Trim and Fill and PET-PEESE were widely used. Methodologists now strongly advise against relying on Trim and Fill, as it is known to falsely impute studies and over-adjust when true between-study heterogeneity (rather than bias) is the actual cause of the asymmetry. Similarly, modern simulations show that PET-PEESE can suffer from severe Type I error rates and erratic adjustments at typical behavioral science sample sizes. They should only be reported as secondary sensitivity analyses, never as the primary bias adjustment method.
In a recent review of published meta-analyses in clinical psychology, the median adherence to PRISMA reporting guidelines was only roughly 71% (19 out of 27 items), with significant variation across journals. This indicates that systematic gaps in reporting critical methodological details—such as full search strategies and comprehensive risk-of-bias assessments—are unfortunately common in the literature.
PRISMA Reporting Standards and Quality Assessment
Reporting transparency is what separates a reproducible synthesis from an unverifiable narrative. PRISMA 2020 (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) is the current reporting standard, featuring an expanded checklist with specific item/sub-item recommendations that is substantially more rigorous than earlier versions.
The PRISMA 2020 checklist covers: title and abstract registration, introduction (rationale, objectives), methods (eligibility criteria, information sources, search strategy, selection process, data collection, data items, study risk-of-bias assessment, effect measure specification, synthesis methods, reporting bias assessment, certainty assessment), results (study selection with PRISMA flow diagram, study characteristics, risk-of-bias assessment, individual study results, synthesis results, reporting bias, certainty of evidence), and discussion sections.
Risk-of-bias assessment tools most commonly paired with psychological and clinical meta-analyses include:
- RoB 2 (Cochrane): For randomized controlled trials, covering randomization, deviations from interventions, missing outcome data, measurement of outcomes, and selection of reported results.
- ROBINS-I: For evaluating non-randomized studies of interventions.
- AMSTAR-2: For evaluating the methodological quality of the systematic review itself (not the included studies) — the tool where nearly 70% of reviews failed to adequately document their study design selection rationale.
Parity reporting — documenting that effect size computations are consistent across statistical software implementations — is increasingly expected in high-quality syntheses. The Compute.es parity report provides this exact layer of documentation, cross-validating outputs against reference implementations to ensure absolute accuracy.
Open-Source Statistical Infrastructure for Meta-Analysis
The gap between knowing the statistical formulas and executing a clean, reproducible effect size database is where most researchers lose valuable time. Open-source tools like the compute.es R package address this by providing a programmatic framework that handles every standard conversion a meta-analyst will encounter.
The conversion modules available in these packages include means and SDs, t-tests, one-way F-tests, p-values, ANCOVA-based effect sizes, binary data (OR, risk difference, NNT), correlation r, and advanced non-parametric conversions.
Every output includes the standard error and 95% CI, making the database immediately ready for model fitting in metafor or MAd — skipping intermediate transformation steps and preventing manual formula re-entry errors. This approach brings the principles of open science and reproducibility directly to the data extraction stage, where it matters most for synthesis validity.
The design behind these tools reflects the need to bridge academic rigor with applied consulting timelines: the formulas are sourced from primary statistical references (Cohen 1988, Borenstein et al. 2009, Lipsey & Wilson 2001), the outputs are documented in parity reports for reproducibility, and the interfaces are built to minimize user error.
Reproducible Research: From Effect Size Extraction to Publication
A modern meta-analysis should be fully reproducible from raw data extraction through the final forest plot. The alternative—undocumented spreadsheet transformations feeding into manually formatted tables—introduces error at every stage and is impossible to audit when peer reviewers ask for sensitivity analyses.
The standard reproducible synthesis process consists of:
- Protocol registration (PROSPERO or OSF) before screening begins.
- Systematic database search with documented search strings (stored in supplementary materials or the OSF project).
- Dual-independent screening with inter-rater reliability reporting (Cohen’s kappa for title/abstract and full-text stages).
- Standardized data extraction to a CSV or structured spreadsheet — means, SDs, sample sizes, t/F statistics, binary counts, as available per study.
- Effect Size computation via a documented tool (such as the
compute.esR package for batch processing or its browser-based equivalent) with parity verification. - Model fitting in R via
metafor::rma()(fixed/random effects) ormetafor::rma.mv()(multilevel/multivariate models), typically using REML as the default estimator for τ². - Report rendering via Quarto (.qmd) or RMarkdown to produce a transparent, reproducible report with embedded forest plots, funnel plots, and heterogeneity summary tables — completely avoiding copy-pasting from the R console to Word.
This is precisely the kind of system that transforms a one-time synthesis project into a reusable template. When new studies are published, updating the synthesis simply means adding rows to the effect size spreadsheet and re-rendering the Quarto document, rather than rebuilding the analysis from scratch. The consulting services offered through Del Re Data & Statistical Consulting are built around this exact reproducible architecture.
Conclusion: Applying Meta-Analysis Fundamentals and Core Methodologies
Conducting a meta-analysis requires more than basic familiarity with Cohen’s d thresholds. It requires precise effect size computation across multiple conversion methods (d, g, r, OR), correct model specification for dependent data structures (multilevel frameworks, REML estimation), rigorous heterogeneity interpretation through prediction intervals rather than I² alone, transparent publication bias assessment, and a fully reproducible workflow from the initial extraction spreadsheet to the published Quarto report.
The statistical tools for all of this exist and are readily accessible. The compute.es package handles every standard conversion with documented formulas, automatic standard error and 95% CI computation, and parity verification. The R package MAd is extremely useful for structuring dependent data, while metafor powers the underlying statistical modeling. Quarto handles the reporting layer. What remains is the methodological judgment to connect these components correctly — and that judgment is what the meta-analysis course and resources at this site are designed to build.
The research synthesis literature is unambiguous: syntheses that skip prediction intervals, omit publication bias assessments, or fail to document study design selection rationale produce conclusions that are less reliable than the effort invested in them suggests. Methodological rigor, applied systematically at every stage of the synthesis, is what closes that gap.
Summary
Ultimately, a high-quality meta-analysis requires a combination of theoretical precision and computational transparency. By relying on rigorous reporting standards (like PRISMA), leveraging structured data workflows (compute.es), properly specifying variance (metafor), and evaluating prediction intervals and publication bias, researchers can deliver clinical insights that hold true beyond their original sample.
Frequently Asked Questions
What are the core methodologies of meta-analysis?
The core methodologies of meta-analysis include effect size extraction and computation (Cohen’s d, Hedges’ g, Pearson’s r, Odds Ratios), inverse-variance weighting, fixed-effects and random-effects model specification, heterogeneity assessment via I², Q, tau², and prediction intervals, and publication bias detection through funnel plot analysis, Egger’s test, and Selection Models. Each methodology connects directly to the quality and interpretability of the pooled estimate.
What is the difference between Cohen’s d and Hedges’ g in meta-analysis?
Cohen’s d is the standardized mean difference between two groups and is the most widely reported effect size in behavioral research. Hedges’ g applies a small-sample correction factor to Cohen’s d, producing a more conservative and unbiased estimate of the population effect size — the correction matters most when N < 20 per group and is mathematically negligible at larger sample sizes.
How do I calculate an effect size from a published t-statistic or F-statistic?
From a t-statistic, use d = t × √(1/n₁ + 1/n₂); from a one-df F-statistic, use d = √(F × (1/n₁ + 1/n₂)). The compute.es package automates both conversions and outputs the standard error and 95% CI alongside d, g, r, and OR simultaneously.
Is I² a good measure of heterogeneity in meta-analysis?
I² quantifies the proportion of variance attributable to between-study heterogeneity rather than sampling error, but it is not an absolute measure of heterogeneity — it does not tell you how wide the distribution of true effects is in the original metric. Prediction intervals provide a more clinically and practically relevant summary and should accompany I² in any heterogeneity report.
What R packages are used for meta-analysis in 2026?
metafor serves as the core statistical engine for both standard and multilevel meta-analytic models, utilizing rma() for fixed/random effects and rma.mv() for dependent effect sizes. The MAd package acts as a highly specialized tool for data preparation and dependency structuring before feeding the data into the metafor models. Both integrate smoothly with databases compiled via compute.es.
How do I handle dependent effect sizes in a meta-analysis?
Dependent effect sizes arise when a single study contributes multiple outcomes from the same sample. The standard solution is the three-level multilevel meta-analytic model (implemented via metafor::rma.mv()), which partitions variance at the within-study and between-study levels separately. Best practice dictates fitting this multilevel model first to borrow strength across dependent effect sizes, and then applying robust variance estimation (RVE) to the standard errors (e.g., via the clubSandwich package) to protect against misspecification of the exact dependency structure.
What is a prediction interval in meta-analysis and why does it matter?
A prediction interval (PI) is a 95% range within which the true effect size of a new, comparable study would fall — it directly translates heterogeneity into the original effect size metric. A PI is far more interpretable for practitioners than I² alone because it answers the applied clinical question: if I implement this intervention in my specific context, what effect range should I realistically expect?